|
|
@@ -35,43 +35,129 @@ Very similar to producer.
|
|
|
- manual, self-administering mode
|
|
|
- more of an advanced case
|
|
|
- does not needs a `group.id`
|
|
|
-- blocks instead of erroring if one of the partitions does not exist, in
|
|
|
+- blocks instead of erroring if one of the partitions does not exist, in
|
|
|
`updateFetchPositions.updateFetchPositions()` (see poll loop below).
|
|
|
|
|
|
-
|
|
|
## The poll loop
|
|
|
|
|
|
- primary function of the `KafkaConsumer`
|
|
|
- continuously poll the brokers for data
|
|
|
- single API for handling all Consumer <-> Broker interactions
|
|
|
- a lot of interactions beyond message retrieval
|
|
|
-- when `consumer.assign()` or `.subscribe()` is called, the contents of the topics
|
|
|
- and partitions collections in metadata are used to set fields within the
|
|
|
+- when `consumer.assign()` or `.subscribe()` is called, the contents of the topics and partitions collections in
|
|
|
+ metadata are used to set fields within the
|
|
|
`SubscriptionState consumer.subscriptions` field
|
|
|
- - this value is the source of truth for everything the consumer is assigned to
|
|
|
- - most consuming operations interact with it and the `ConsumerCoordinator consumer.coordinator` field
|
|
|
-- when `consumer.poll()` is invoked, it uses properties (starting with the `bootstrap.servers`) to
|
|
|
- request metadata about the cluster.
|
|
|
-- the `Fetcher<K, V> consumer.fetcher` performs several fetch-related operations
|
|
|
- between consumer and cluster
|
|
|
+ - this value is the source of truth for everything the consumer is assigned to
|
|
|
+ - most consuming operations interact with it and the `ConsumerCoordinator consumer.coordinator` field
|
|
|
+- when `consumer.poll()` is invoked, it uses properties (starting with the `bootstrap.servers`) to request metadata
|
|
|
+ about the cluster.
|
|
|
+- the `Fetcher<K, V> consumer.fetcher` performs several fetch-related operations between consumer and cluster
|
|
|
- it delegates actual communication to the `ConsumerNetworkClient consumer.client`
|
|
|
- - that consumer, in addition to the actual requests, performs the heartbeats
|
|
|
- informing the cluster of the client health
|
|
|
- - the fetch also requests (via the CNC) the cluster metadata, initially then
|
|
|
- periodically afterwards
|
|
|
+ - that consumer, in addition to the actual requests, performs the heartbeats informing the cluster of the client
|
|
|
+ health
|
|
|
+ - the fetch also requests (via the CNC) the cluster metadata, initially then periodically afterwards
|
|
|
- it obtains information about what topics/partitions are available from the
|
|
|
`SubscriptionState`
|
|
|
-- the `ConsumerCoordinator consumer.coordinator` uses the metadata to coordinate
|
|
|
- the consumer.
|
|
|
+- the `ConsumerCoordinator consumer.coordinator` uses the metadata to coordinate the consumer.
|
|
|
- handles automatic/dynamic partition reassignment by notifying them to the SubscriptionState
|
|
|
- - committing offsets to the cluster so the cluster is aware of the state of subscriptions,
|
|
|
- for each topic and partition.
|
|
|
-- the timeout applies to the time the CNC spends polling the cluster for messages
|
|
|
- to return. It does not apply to the initial setup operations (hence poll remaining
|
|
|
- stuck on nonexistent partitions during the initial update)
|
|
|
+ - committing offsets to the cluster so the cluster is aware of the state of subscriptions, for each topic and
|
|
|
+ partition.
|
|
|
+- the timeout applies to the time the CNC spends polling the cluster for messages to return. It does not apply to the
|
|
|
+ initial setup operations (hence poll remaining stuck on nonexistent partitions during the initial update)
|
|
|
- it is a minimum amount of time the cycle will take, not a maximum
|
|
|
- when the timeout expires, a batch of records are returned
|
|
|
- - they are parsed, deserialized, and stored by topic and partition internally
|
|
|
- in the Fetcher
|
|
|
+ - they are parsed, deserialized, and stored by topic and partition internally in the Fetcher
|
|
|
- once this is done, the fetcher returns this result for application processing.
|
|
|
-
|
|
|
+
|
|
|
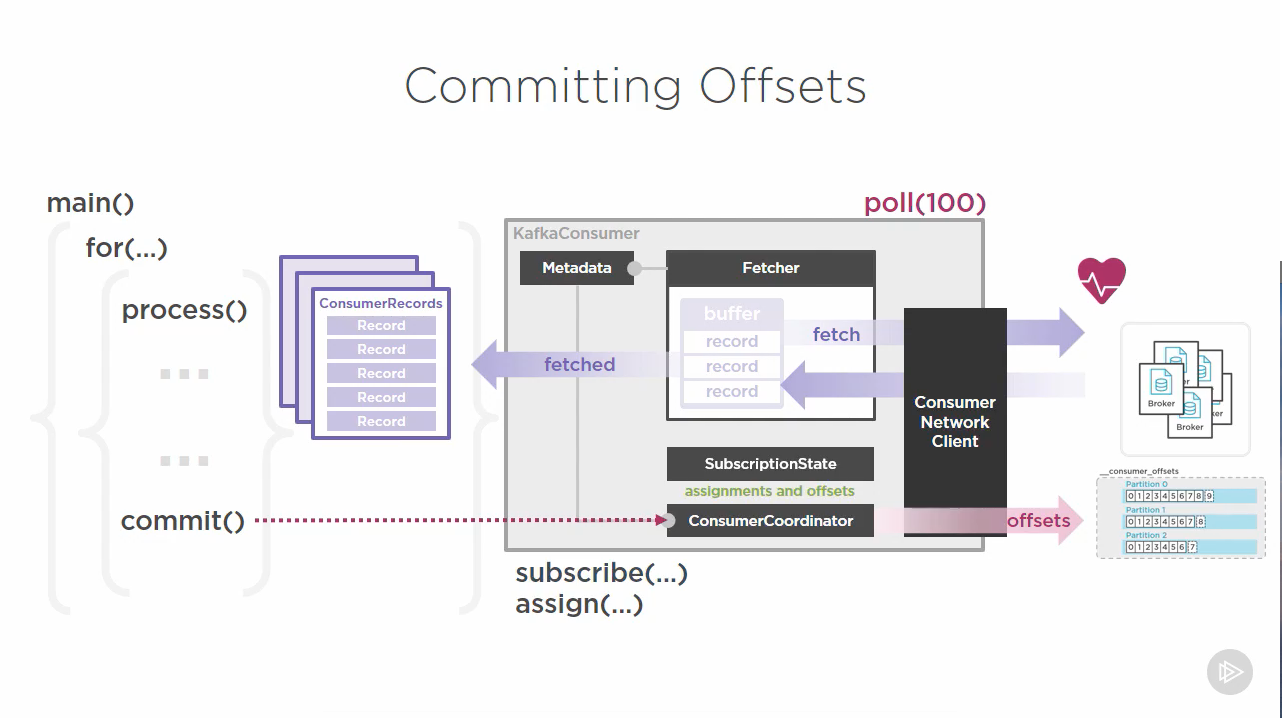
+The `poll()` process is a single-threaded operation:
|
|
|
+
|
|
|
+- 1 poll loop per-consumer
|
|
|
+- 1 thread per-consumer
|
|
|
+
|
|
|
+This is for internal simplicity and to force parallel consumption to be performed otherwise.
|
|
|
+
|
|
|
+## Processing messages
|
|
|
+
|
|
|
+The `poll()` method returns a `ConsumerRecords`, a collection of `ConsumerRecord`:
|
|
|
+
|
|
|
+```java
|
|
|
+public class ConsumerRecords<K, V> implements Iterable<ConsumerRecord<K, V>> {
|
|
|
+ /* ... */
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+- Since the `poll()` runs in a single thread, there is nothing running while the records are being processed
|
|
|
+- The more topics and partitions a single process subscribes to, the more it has to do within that single polling loop,
|
|
|
+ which can make the consumer slow
|
|
|
+
|
|
|
+## Offsets and positions
|
|
|
+
|
|
|
+Just because something is _read_ does not mean it is _committed_:
|
|
|
+
|
|
|
+
|
|
|
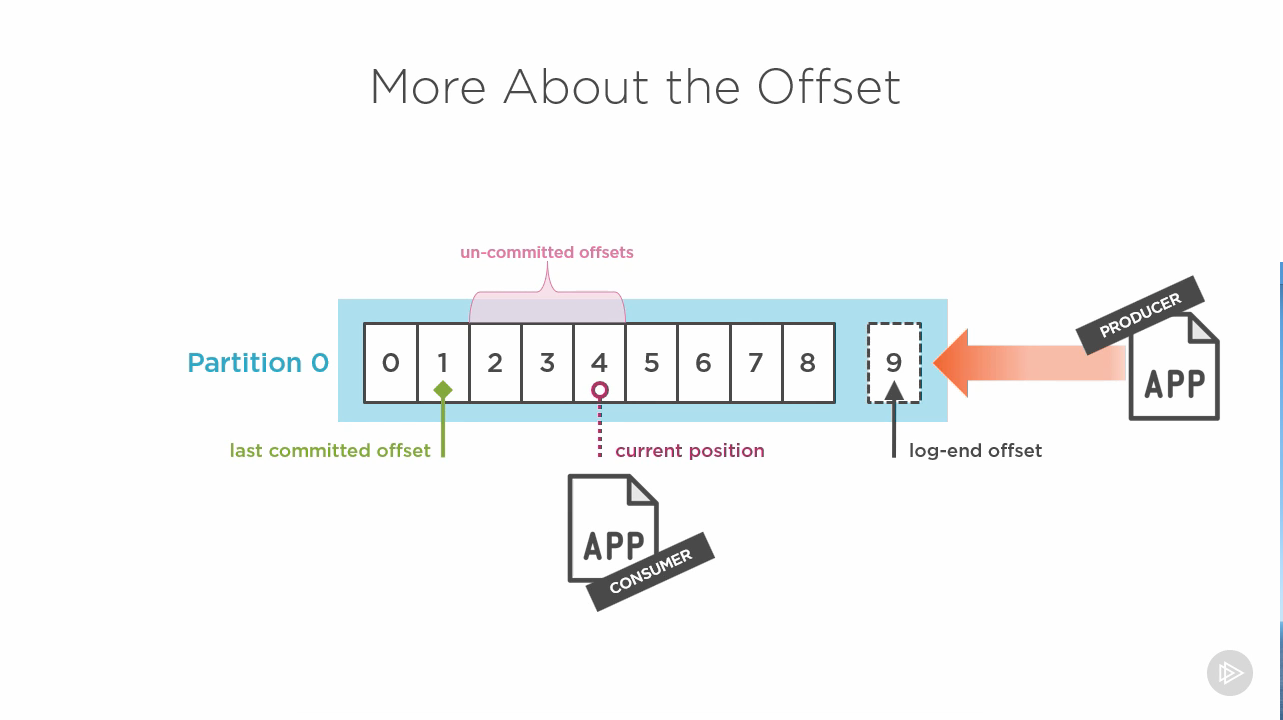
+- There are different categories of offsets, representing the stage they're in:
|
|
|
+ - a consumer needs to know what it has vs has not read
|
|
|
+ - what it confirms it has read (and processed) is the _last committed offset_
|
|
|
+ - this is whence consuming starts for a given partition, subject to offset reset
|
|
|
+- Each partition is exclusive with regard to consumer offsets: for any topic, a
|
|
|
+ consumer is tracking one offset per partition it is subscribed to
|
|
|
+- Consumers read at the _current position_ towards the _log-end offset_.
|
|
|
+- Offsets from the last committed to the current position are _uncommitted_.
|
|
|
+- Two **optional** offset commit properties control these offsets:
|
|
|
+ - `enable.auto.commit` lets Kafka decide when current position offsets are
|
|
|
+ upgraded to full committed offsets. Defaults to `true`.
|
|
|
+ - Since it has no knowledge of what work is actually performed, it can only
|
|
|
+ use a delay for that. That delay is the `auto.commit.interval`, in msec,
|
|
|
+ which defaults to 5000, which is a lot for high-throughput cases.
|
|
|
+
|
|
|
+<blockquote>
|
|
|
+The extent to which your system can be tolerant of eventual consistency
|
|
|
+is detemined by its reliability.
|
|
|
+</blockquote>
|
|
|
+
|
|
|
+By default, consumers start reading from a new partition at the `latest` committed offset.
|
|
|
+
|
|
|
+- Optional property:
|
|
|
+ - `auto.offset.reset` can be `earliest`, `latest` (default), or `none` which
|
|
|
+ throws an exception and lets code decide.
|
|
|
+
|
|
|
+Offset choice is different depending on whether the topology has a single consumer,
|
|
|
+or a ConsumerGroup.
|
|
|
+
|
|
|
+- Kafka stores offsets in a special topic called `__consumer_offsets`, with 50 partitions.
|
|
|
+- They are produced by the `ConsumerCoordinator`, which means a Consumer is also
|
|
|
+ a Producer, but for just that topic. Once they have been committed, the coordinator
|
|
|
+ updates the SubscriptionState accordingly, allowing the Fetch to know which
|
|
|
+ offsets it should be retrieving.
|
|
|
+
|
|
|
+## Manual committing
|
|
|
+
|
|
|
+There are two methods to commit:
|
|
|
+
|
|
|
+- `commitSync()`: used to achieve exact control of when the record is truly processed;
|
|
|
+ when one doesn't want to process newer records until the older ones are committed.
|
|
|
+ - It should be called after processing a **batch** of ConsumerRecord, not just a
|
|
|
+ single record, which increases latency to no avail
|
|
|
+ - It blocks until it receives a response from the cluster
|
|
|
+ - It may fail, meaning a recovery process must be started. It retries automatically
|
|
|
+ until it succeeds, or it receives an unrecoverable error.
|
|
|
+ - The `retry.backoff.ms` == `RETRY_BACKOFF_MS_CONFIG` (default: 100) property defines the retry delay, similarly
|
|
|
+ to the producer backoff (for good reason)
|
|
|
+ - Using this manual committing is a tradeoff between throughput/performance (less)
|
|
|
+ and control over consistency (more), as this adds some latency to the polling
|
|
|
+ process.
|
|
|
+- `commitAsync()`
|
|
|
+ - does not retry automatically, because it can't know whether the previous
|
|
|
+ commit succeeded or failed, which could lead to ordering and duplication issues
|
|
|
+ - instead, it accepts a callback, triggered on receiving the commit response
|
|
|
+ from the cluster.
|
|
|
+ - better throughput because it doesn't block the polling process.
|
|
|
+ - Don't use it without registering the callback and handling it as needed.
|
|
|
+
|
|
|
+## Deciding on a commit strategy
|
|
|
+
|
|
|
+- Consistency control:
|
|
|
+ - need to know when something is "done" (define "done" first)
|
|
|
+- Atomicity:
|
|
|
+ - ability to treat consumption and processing as a single atomic operation
|
|
|
+ - obtaining _exactly-once_ semantics instead of _at-least-once_
|


{kind=link}
{kind=link}