|
|
@@ -94,7 +94,6 @@ public class ConsumerRecords<K, V> implements Iterable<ConsumerRecord<K, V>> {
|
|
|
|
|
|
Just because something is _read_ does not mean it is _committed_:
|
|
|
|
|
|
-
|
|
|
- There are different categories of offsets, representing the stage they're in:
|
|
|
- a consumer needs to know what it has vs has not read
|
|
|
- what it confirms it has read (and processed) is the _last committed offset_
|
|
|
@@ -119,7 +118,7 @@ By default, consumers start reading from a new partition at the `latest` committ
|
|
|
|
|
|
- Optional property:
|
|
|
- `auto.offset.reset` can be `earliest`, `latest` (default), or `none` which
|
|
|
- throws an exception and lets code decide.
|
|
|
+ throws an exception and lets code decide. See "rebalancing" below.
|
|
|
|
|
|
Offset choice is different depending on whether the topology has a single consumer,
|
|
|
or a ConsumerGroup.
|
|
|
@@ -161,3 +160,67 @@ There are two methods to commit:
|
|
|
- Atomicity:
|
|
|
- ability to treat consumption and processing as a single atomic operation
|
|
|
- obtaining _exactly-once_ semantics instead of _at-least-once_
|
|
|
+
|
|
|
+## Scaling out consumers
|
|
|
+
|
|
|
+- Scaling a single-thread, single-consumer app to the bandwidth, number of topics
|
|
|
+ and partitions of a full K cluster is not realistic
|
|
|
+- The solution is to scale out consuming to more consumers, but they can't jusst
|
|
|
+ consumer anything without synchronizing in some way
|
|
|
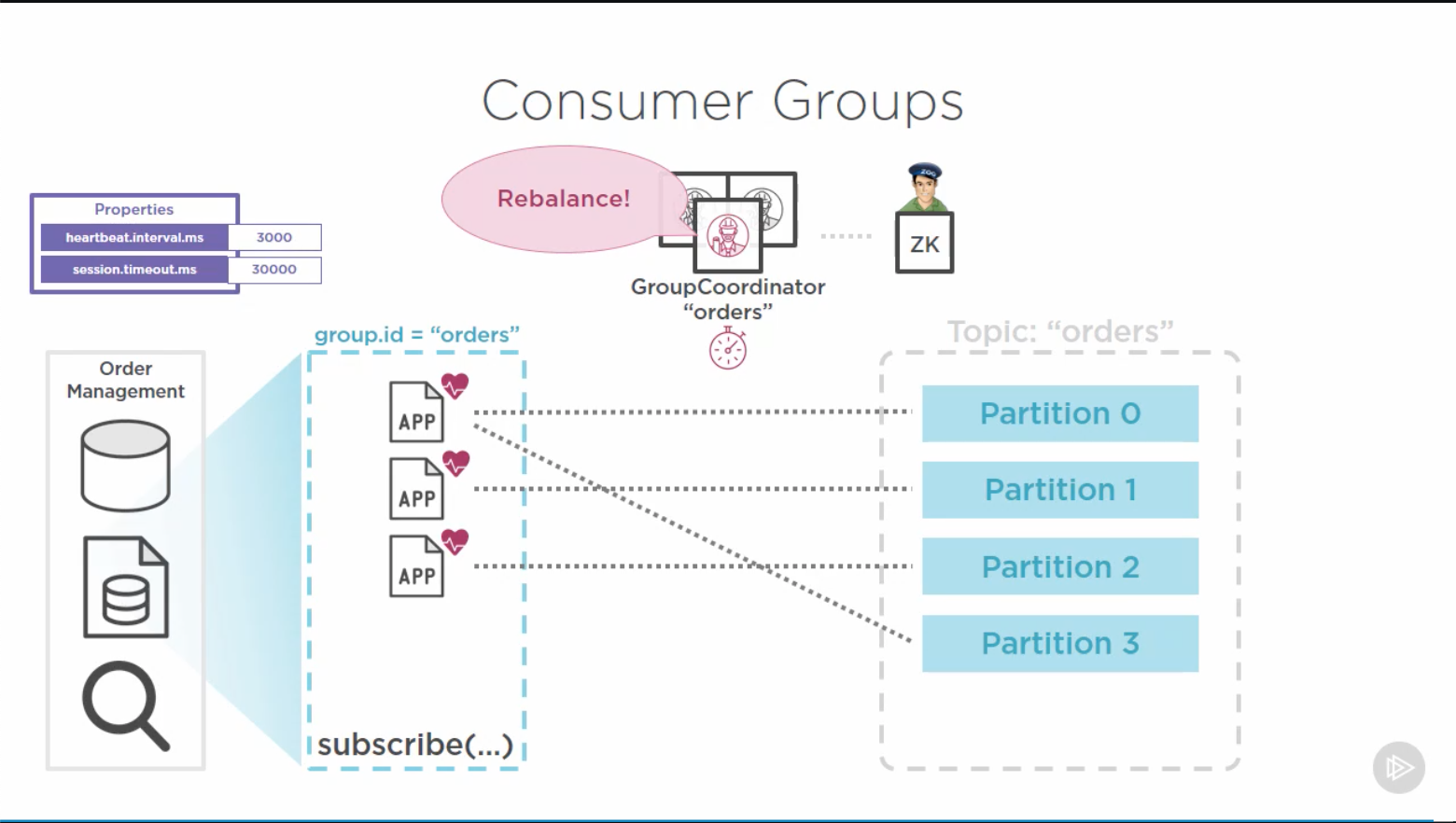
+- This is the reason for Consumer groups: a collection of independent Consumer
|
|
|
+ working as a team, i.e. declaring the same `group.id`.
|
|
|
+ - This allows them to share the message consumption and processing load, with more parallelism.
|
|
|
+ - It allows more redundancy: failure or limitations of a given consumer are
|
|
|
+ automatically handled and balanced by K.
|
|
|
+ - It offers more performance, with the ability to support a large backlog
|
|
|
+- A Consumer group is create when individual consumers
|
|
|
+ - with a commmon `group.id`...
|
|
|
+ - invoke the `subscribe()` method...
|
|
|
+ - and pass a common topics list.
|
|
|
+- One of the brokers gets elected as the `GroupCoordinator` for that topic.
|
|
|
+ - Its job is to monitor and maintain group membership.
|
|
|
+ - It collaborates with the `ClusterCoordinator` and ZooKeeper to monitor and
|
|
|
+ assign partitions within a topic to individual consumers in the group.
|
|
|
+- As soon as a Consumer group is formed, each consumer is sending heartbeats,
|
|
|
+ - configured by properties:
|
|
|
+ - `heartbeat.interval.ms` == `HEARTBEAT_INTERVAL_MS_CONFIG` (default 3000 msec):
|
|
|
+ the interval between heartbeat sends
|
|
|
+ - `session.timeout.ms` == `SESSION_TIMEOUT_MS_CONFIG` (default 30000 msec)
|
|
|
+ - the CG coordinator relies on these heartbeats to evalue whether the consumer
|
|
|
+ is alive and able to participate in the group
|
|
|
+ - if the coordinator does not receive heartbeat during a "total time" (?)
|
|
|
+ larger than `session.timeout.ms`, it will consider the consumer failed and take
|
|
|
+ corrective action, following its priority: ensuring that the purpose of the
|
|
|
+ group (sharing the load of consuming those topics) is being met.
|
|
|
+ - these corrections are _consumer rebalance_ operations, which is complex
|
|
|
+ - remaining consumers now need to absorb the workload no longer handled
|
|
|
+ by the failed consumer
|
|
|
+ - they need to find up to where the failed consumer had worked (commit offset)
|
|
|
+ for all partitions, and catch up without creating duplicates.
|
|
|
+ - the ability to perform these rebalances is critical to cluster health.
|
|
|
+ - example 1: the failed consumer handled messages but could not commit
|
|
|
+ them; in that case the new consumer are likely to re-process them,
|
|
|
+ possibly introducing duplicates
|
|
|
+ - example 2: a new consumer joins the group
|
|
|
+ - example 3: a new partition is added to the topic
|
|
|
+- Applications are configured with a consumer group to handle their topics
|
|
|
+
|
|
|
+## Rebalancing
|
|
|
+
|
|
|
+The offset at which a new consumer in a group starts consuming is defined by
|
|
|
+the `auto.offset.reset` == `AUTO_OFFSET_RESET_CONFIG` property.
|
|
|
+
|
|
|
+If the rebalance was triggered at a point when a previous consumer had already
|
|
|
+read but not yet committed some offset, the new consumer is likely to read it again.
|
|
|
+
|
|
|
+The primary purpose of the Group Coordinator is to evenly ablance available consumers
|
|
|
+to partitions.
|
|
|
+
|
|
|
+- If possible, it will assign a 1:1 consumer/partition ratio.
|
|
|
+- If there are more consumers than partitions, it will let the extra consumers idle,
|
|
|
+ leading to over-provisioning
|
|
|
+ - Apparently (to be confirmed), even if there are more partitions than consumers,
|
|
|
+ it will not share a partition across multiple consumers
|
|
|
+- If a new partition becomes available, or a consumer fails, or is added,
|
|
|
+ the Group Coordinator initiates the rebalancing protocol, engaging each Consumer coordinator
|
|
|
+
|


{kind=link}